서론
안녕하세요 앞으로 Flutter에 대해 공부하도록 하겠습니다.
Flutter는 앱 뿐만아니라 웹페이지,윈도우 데스크탑 프로그램도도 만들수있으며
배우기 쉽고, 개발언어가 구글에서 만든 Dart언어인데 앱개발시 Dart언어 단 하나만 배우면 된다는 장점이있습니다.
글을 읽기 전에 저는 컴공과에 재학중인 대학생입니다. 따라서 글에 틀린부분이 있을수 있다는점 양해 부탁드립니다.
설치
https://flutter-ko.dev/docs/get-started/install/windows#
윈도우에서 설치
flutter-ko.dev
이 사이트에 들어가서 Flutter SDK를 다운받아야되는데 저같은경우 다운로드 버튼이 Failed로 돼있어서 다운로드가 불가능하였습니다.
해결방법은 플러터 공식사이트https://flutter.dev/ 로 접속해서 다운받는 방식입니다...(간단)
그 후 환경변수에 들어가셔서 Path에 추가해주셔야 되는데
flutter에서 압축을 해제하여 flutter폴더에있는 bin폴더의 경로를 추가해주면됩니다.
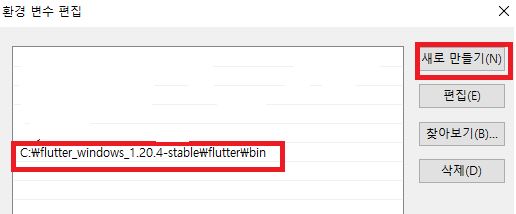
그 후 안드로이드 스튜디오는 설치되어있다고 가정하고
안드로이드 스튜디오에서 flutter 플러그인 설치하시면 끝입니다.
설치과정을 영상으로 자세히 보고싶으신분은 코딩애플님의 영상을 추천드립니다.
https://www.youtube.com/watch?v=JS-Si5GO3iA
실습
1. Hello World !
- Flutter에서는 화면을 그리는 모든 디자인 요소를 위젯(Widget)이라고 함
플러터는 lib/main.dart가 메인 화면입니다.
코딩의 시작 Hello World를 화면에 표시하고싶으시면
#appbar의 title은 Welcome to Flutter
#center의 text는 Hello World로 바꾼 코드
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text('Welcome to Flutter'),
),
body: Center(
child: Text('Hello World'),
),
),
);
}
}
2. 외부 패키지 이용하기
플러터의 의존성은 pubspec.yaml파일이 담당합니다.
dependencies:
flutter:
sdk: flutter
cupertino_icons: ^0.1.2
english_words: ^3.1.0cupertino는 UI가 IOS스러운 앱을 만들때 사용하는 디자인
종속성을 추가해준다음 Pub get을 해줘야함
패키지를 가져올때 import 를 사용함.
lib/main.dart 파일에 다음과같이 패키지를 가져와준다
import 'package:english_words/english_words.dart';
"Hello World" 문자열출력대신 English words를 사용하여 텍스트를 생성해보도록 합시다.
@override
Widget build(BuildContext context) {
final wordPair = WordPair.random();
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text('Welcome to Flutter'),
),
body: Center(
child: Text(wordPair.asPascalCase),
),
),
);
}
Stateful 위젯 추가하기
Stateless 위젯은 모두 변경불가능함. 즉 모든값이 final 이다.
Stateful 위젯은 위젯의 수명동안 변경될 수 있는 상태를 유지합니다. Stateful 위젯은 최소 두 개 이상 클래스가 필요합니다: 1) StatefulWidget 클래스가 2) State 클래스 의 인스턴스를 생성합니다. StatefulWidget 클래스 그자체는 변경불가능합니다. 하지만 State 클래스가 위젯의 수명동안 상태를 유지합니다.
앱의 수명동안 변경될수있는 위젯 RandomWords를 추가하고 그위젯에서 State클래스인 RandomWordsState를 생성할것이다. 그 후 RandomWords를 기존 Stateless위젯 MyApp 의 자식으로 사용될 것임
class RandomWordsState extends State<RandomWords> {
// TODO Add build() method
}
class RandomWords extends StatefulWidget {
@override
RandomWordsState createState() => RandomWordsState();
}
Randomwordsstate 수정
class RandomWordsState extends State<RandomWords> {
@override
Widget build(BuildContext context) {
final wordPair = WordPair.random();
return Text(wordPair.asPascalCase);
}
}
전체코드
import 'package:flutter/material.dart';
import 'dart:async';
import 'package:flutter/services.dart';
import 'package:flutter_plugin2/flutter_plugin2.dart';
import 'package:english_words/english_words.dart';
void main() {
runApp(const MyApp());
}
class MyApp extends StatefulWidget {
const MyApp({Key? key}) : super(key: key);
@override
State<MyApp> createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
String _platformVersion = 'Unknown';
@override
void initState() {
super.initState();
initPlatformState();
}
// Platform messages are asynchronous, so we initialize in an async method.
Future<void> initPlatformState() async {
String platformVersion;
// Platform messages may fail, so we use a try/catch PlatformException.
// We also handle the message potentially returning null.
try {
platformVersion =
await FlutterPlugin2.platformVersion ?? 'Unknown platform version';
} on PlatformException {
platformVersion = 'Failed to get platform version.';
}
// If the widget was removed from the tree while the asynchronous platform
// message was in flight, we want to discard the reply rather than calling
// setState to update our non-existent appearance.
if (!mounted) return;
setState(() {
_platformVersion = platformVersion;
});
}
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: const Text('Welcome to Flutter'),
),
body: Center(
child: RandomWords(),
),
),
);
}
}
class RandomWordsState extends State<RandomWords> {
@override
Widget build(BuildContext context) {
final wordPair = WordPair.random();
return Text(wordPair.asPascalCase);
}
}
class RandomWords extends StatefulWidget {
@override
RandomWordsState createState() => RandomWordsState();
}
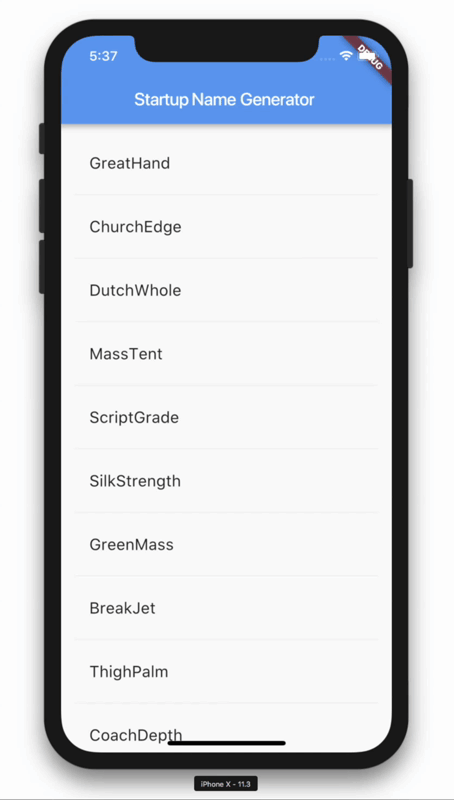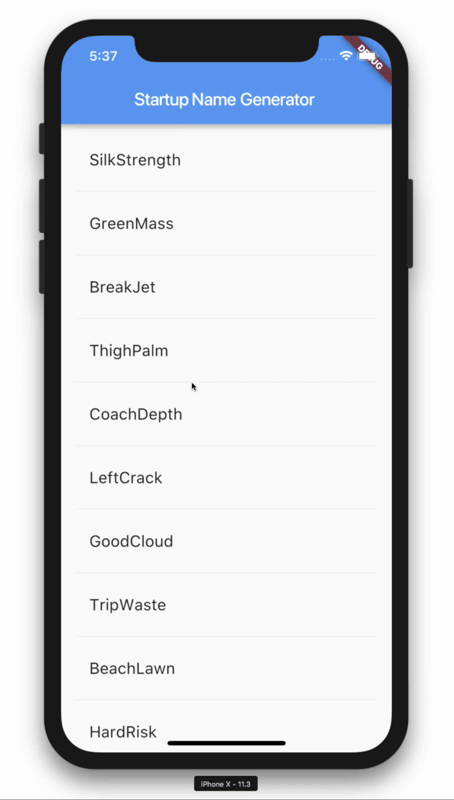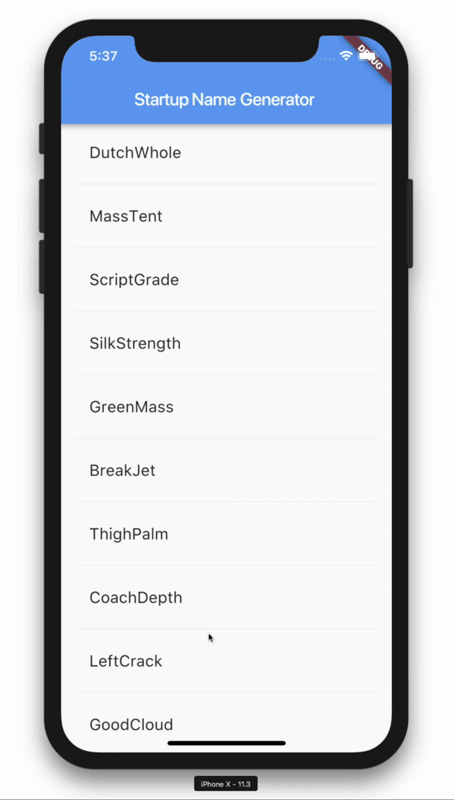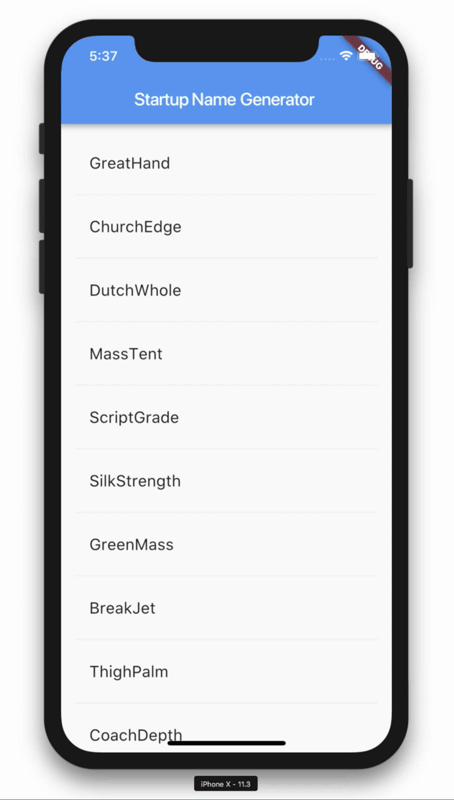
이렇게 코드를 짜시면 앱이 실행될때마다 중앙화면에 영단어가 랜덤으로 출력됩니다.
리스트뷰를 이용한 랜덤 영단어 생성기
import 'package:flutter/material.dart';
import 'dart:async';
import 'package:flutter/services.dart';
import 'package:flutter_plugin2/flutter_plugin2.dart';
import 'package:english_words/english_words.dart';
void main() {
runApp(const MyApp());
}
class MyApp extends StatefulWidget {
const MyApp({Key? key}) : super(key: key);
@override
State<MyApp> createState() => _MyAppState();
}
class _MyAppState extends State<MyApp> {
String _platformVersion = 'Unknown';
@override
void initState() {
super.initState();
initPlatformState();
}
// Platform messages are asynchronous, so we initialize in an async method.
Future<void> initPlatformState() async {
String platformVersion;
// Platform messages may fail, so we use a try/catch PlatformException.
// We also handle the message potentially returning null.
try {
platformVersion =
await FlutterPlugin2.platformVersion ?? 'Unknown platform version';
} on PlatformException {
platformVersion = 'Failed to get platform version.';
}
// If the widget was removed from the tree while the asynchronous platform
// message was in flight, we want to discard the reply rather than calling
// setState to update our non-existent appearance.
if (!mounted) return;
setState(() {
_platformVersion = platformVersion;
});
}
@override
Widget build(BuildContext context) {
return MaterialApp(
home: Scaffold(
appBar: AppBar(
title: Text('My Project01'),
),
body: RandomWords(),
),
);
}
}
class RandomWordsState extends State<RandomWords> {
final _suggestions = <WordPair>[];
final _biggerFont = const TextStyle(fontSize:18.0);
Widget _buildSuggestions() {
return ListView.builder(
padding: const EdgeInsets.all(16.0),
itemBuilder: /*1*/ (context, i) {
if (i.isOdd) return Divider(); /*2*/
final index = i ~/ 2; /*3*/
if (index >= _suggestions.length) {
_suggestions.addAll(generateWordPairs().take(10)); /*4*/
}
return _buildRow(_suggestions[index]);
});
}
Widget _buildRow(WordPair pair) {
return ListTile(
title: Text(
pair.asPascalCase,
style: _biggerFont,
),
);
}
@override
Widget build(BuildContext context) {
final wordPair = WordPair.random();
return Scaffold(
body: _buildSuggestions(),
);
}
}
class RandomWords extends StatefulWidget {
@override
RandomWordsState createState() => RandomWordsState();
}
본글은